你的位置:开云官网登录入口 开云app官网入口 > 新闻 >
体育游戏app平台据DeepSeek先容-开云官网登录入口 开云app官网入口
发布日期:2025-03-05 16:11 点击次数:122

北京时候2月18日,在马斯克还在庆祝Grok 3模子厚爱发布的时候,DeepSeek官方在酬酢平台X上发布了一篇纯时刻论文,主如果对于原生稀少细致力(Native Sparse Attention,下称NSA),直指ChatGPT等顶尖大模子背后的Transformer架构最中枢的细致力机制。
通过这一时刻,DeepSeek不仅能将大谈话模子经管64k长文本的速率最高升迁11.6倍,更在通用基准测试中完毕了对传统全细致力模子(Full Attention models)的性能反超。
值得细致的是,这篇论文是由DeepSeek创始东谈主梁文锋亲身提交的,而且他亦然作家之一。而就在DeepSeek发表这篇时刻论文的吞并天,月之暗面创始东谈主杨植麟也“挂帅”发布了最新论文,主题相同围绕长文的算法优化。
月之暗面提议的新设施叫块细致力搀杂(Mixture of Block Attention,下称MoBA)。这项设施莫得皆备脱离面前最主流的全细致力机制,而是想象了一套不错解放切换的花样,让这些模子不错在全细致力和稀少细致力机制之间切换,给已有的全细致力模子更多的适配空间。
谈及DeepSeek的NSA机制,风投公司RAI Digital聚首创始东谈主萨义德·戈苏斯对《逐日经济新闻》记者确认称,与马斯克所追求的“粗心出名胜”不同,DeepSeek的新时刻更强调通过算法优化来升迁长文经管恶果。他提到,NSA不会专注每个单词,而是尝试通过只柔和贫寒的单词来升迁恶果。
DeepSeek发布新论文,梁文锋参与并提交
北京时候2月18日,DeepSeek官方在X上发布新论文,先容了一种新的算法优化花样——原生稀少细致力(NSA)。
据DeepSeek先容,NSA专为长文本检修与推盼愿象,能利用动态分层稀少战术等设施,通过针对当代硬件的优化想象,显赫优化传统AI模子在检修和推理经过中的弘扬,额外是升迁长险峻文的推明智商,在保证性能的同期升迁了推理速率,并灵验裁汰了预检修资本。

图片起原:X
通过这一时刻,DeepSeek不仅能将大谈话模子经管64k长文本的速率最高升迁11.6倍,更在通用基准测试中完毕了对传统全细致力模子的性能反超。

图片起原:DeepSeek的X账号
值得细致的是,DeepSeek创始东谈主梁文锋也出面前了论文作家的行列当中,在作家排行中位列倒数第二,何况亦然他亲身提交至预印本网站上的。

图片起原:arXiv
论文的第一作家是DeepSeek的实习生袁景阳,他于2022年在北大取得了学士学位,面前在北大的Anker Embodied AI推行室不时攻读计划生学位。他亦然DeepSeek-V3论说的主要作家之一,并参与了DeepSeek-R1的计划使命。
月之暗面再次“撞车”DeepSeek
忘我有偶,在DeepSeek发论文确今日,月之暗面创始东谈主杨植麟也亲身“挂帅”发表了一篇论文,相同直指算法优化。

杨植麟 图片起原:视觉中国

图片起原:月之暗面
该公司提议的新设施叫块细致力搀杂(MoBA)。顾名念念义,这一设施也应用了将词形成块的设施。不外,该设施莫得皆备脱离面前最主流的全细致力机制,而是想象了一套不错解放切换的花样,让这些模子不错在全细致力和稀少细致力机制之间切换,给已有的全细致力模子更多的适配空间。
左证论文,MoBA的计较复杂度跟着险峻文长度加多而上风较着。在1M token的测试中,MoBA比全细致力快了6.5倍;到10M token时,则提速16倍。而且,它还是在Kimi的居品中使用,用来经管日常用户们的超长险峻文的经管需求。
而这也并不是是DeepSeek和月之暗面第一次“撞车”了,上一次是在DeepSeek推理模子R1和月之暗面推理模子Kimi 1.5发布时。
MoBA论文主要作家章明星教授笑称,“有种‘掌中,亦亡字’的嗅觉(不辩论谁是孔明,谁说周郎)。”他同期也感触:“大模子这套架构最神奇的少许我嗅觉便是它似乎我方就指出了前进的道路,让不同的东谈主从不同的角度得出了相似的前进标的。”
DeepSeek新设施背后的三大时刻
谈及DeepSeek的新设施,风投公司RAI Digital聚首创始东谈主萨义德·戈苏斯告诉每经记者,这是AI模子经管超长文本的新设施,比传统设施更快、更高效。
像ChatGPT这样的大型谈话模子,都使用一种叫“细致力”(Attention)机制的设施来经管文本,2017年谷歌计划员推出的论文《Attention Is All You Need》被觉得是面前统共大模子的基石。
戈苏斯进一步向每经记者确认谈:“想象一下你正在读一册书。要相接一个句子,你不仅要看现时的单词,还要回忆起前边句子中的关联单词,以相接统共实质。AI使用细致力作念近似的事情,这有助于它细目哪些词是贫寒的,以及它们互相之间的关系。传统细致力机制(全细致力)会检察文本中的每个单词,并将其与其他每个单词进行相比。这对于漫笔原来说很好,然而当文本很万古(比如整本书或一份长的法律文献),这个经过就会变得太慢,而且在计较机上运转资本太高。
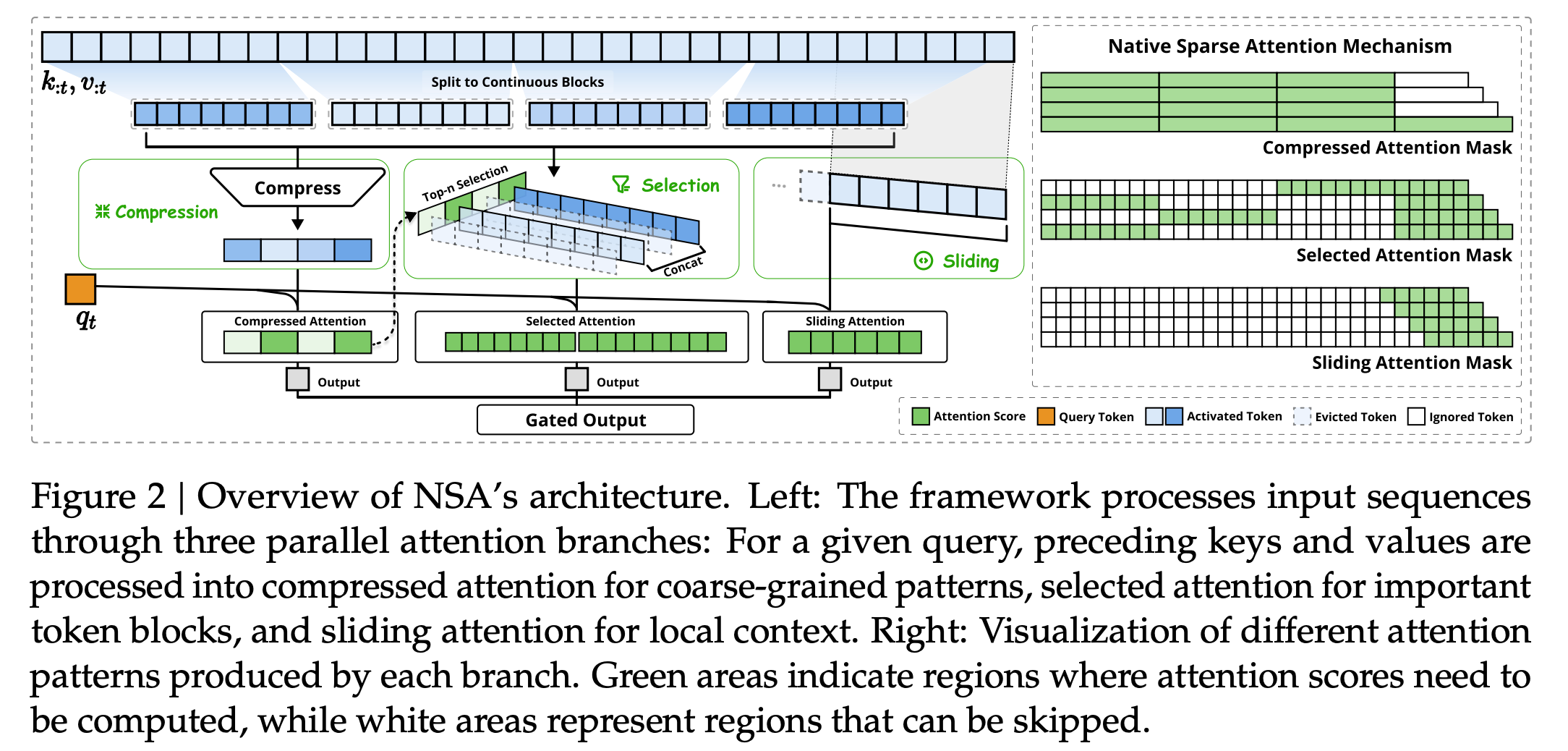
而DeepSeek论文中提到的稀少细致力机制不会专注每个单词,而是尝试通过只柔和贫寒的单词来升迁恶果,就像是只读选录而不是整本书一样。
戈苏斯对每经记者先容说:“为了作念好这少许,NSA引入了一种新设施来过滤不贫寒的单词,同期仍保留充足的险峻文来相接完好意思含义。
它使用三种主要时刻来完毕这少许:
压缩:NSA不会检察每个单词,而是将单词分组为“块”,并为每个块创建选录。不错将其想象成将一个段落形成一个粗心的选录。
遴荐:模子从文本中挑选出最应该柔和的贫寒单词。就像在学习时,只隆起领路教科书中的关节句子一样。
滑动窗口:尽管NSA回来并遴荐了单词,但它仍然会检察隔壁的单词,以确保不会错过轻浅但贫寒的细节。想象一下阅读一册书——东谈主们不会仅仅从一页跳到下一页而不浏览隔壁的句子。
DeepSeek觉得,三部分战术使NSA速率更快,同期相接含义的智商与传统设施一样好(以致更好)。”
图片起原:DeepSeek
有网友称,这是在教授AI学会“灵敏的偷懒”,像东谈主类一样灵敏地分派细致力,从而让长文的经管又快又准,不再是一个“死念书的呆子”。诚然就义了一定的准确率,然而极大升迁了恶果,东谈主脑便是这样干的。
戈苏斯还暴露,DeepSeek这次不仅是单纯的算法超越,它还对现存的计较机硬件进行了优化,以便GPU不错完毕存效经管。
有科技媒体指出,DeepSeek这次使用了Triton框架,而非英伟达专用库体育游戏app平台,这概况暴露了其在模子研发阶段已计议适配更多类型的计较卡,为改日的开源和时时应用奠定了基础。
